데이터 전처리 방법들: 데이터 인코딩, 데이터 스케일링
머신러닝은 데이터의 영향을 많이 받음. 데이터 전처리 중요.
문자열 값을 숫자값으로 바꾸는 것을 인코딩이라고 한다.
척도를 비슷하게 해주는걸 데이터 스케일링.(방개수,거리)
(데이터 인코딩)
머신러닝 알고리즘은 문자열 데이터 속성을 입력받지 않기 때문에 모든 데이터는 숫자형으로 표현되어야 한다. 즉 문자형 속성은 모두 숫자값으로 변환/인코딩 되어야 한다.
1) 레이블 인코딩 LabelEncoder 클래스
각각의 항목이 고유 번호를 부여받았음

fit()과 transform()을 이용하여 변환.
- fit : 데이터 변환을 위한 기준 정보 설정, 매개변수를 이용해서 내부개체상태로 저장. (훈련시킨다 생각)
- transform : fit 정보를 이용해서 데이터를 변환 (변환시킨다 생각)
숫자값은 의도하지 않았는데 0보다 1이 큰.. 어떤 알고리즘의 영향을 받을 수도 있음. 그래서 원-핫인코딩 나옴.
https://colab.research.google.com/drive/1RGGuhcLhIwyNd70IvZ8N3nzafM1rwZol#scrollTo=mfuE6G_SZlwY 회귀분석 과제 진행하면서도 라벨인코딩 방법을 사용하여서 공유함. 프로젝트 코드 계속 업데이트 예정.
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
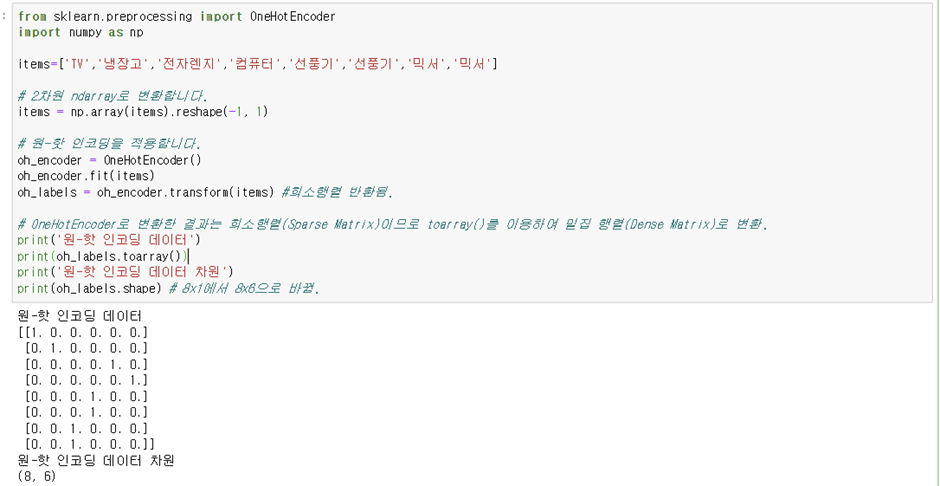
2) 원-핫 인코딩
하나만 1이라는 뜻. 그 값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방법.

OneHotEncoder 클래스 사용. 인자로 2차원 ndarray입력 필요함. toarray()적용하여 다시 Dense형태로 변환.
pd.get_dummies(DataFrame)을 많이 이용함.



희소행렬에 대한 개념이 부족한 경우
쉽게 얘기하면 행렬에 0이 더 많기 때문에 값이 있는 것들만 뽑아서 보겠다 라고 생각하면 쉽다.
https://colab.research.google.com/drive/1boCg30Pl_v_AIli-toH0WH0AqwyWBHSO 코드로 구현한 것이 있으니 참고하시길 바랍니다. 곱에 대한 구현은 차근차근 업데이트 하겠습니다.
'공부기록 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 6주차. XGBoost (0) | 2022.12.19 |
|---|---|
| [머신러닝] 5주차. 앙상블 (0) | 2022.12.19 |
| [머신러닝] 4주차. 결정트리 (0) | 2022.11.11 |
| [머신러닝] 3주차. 정확도, 오차행렬, 정밀도, 재현율 (0) | 2022.11.03 |
| [머신러닝] 1주차. 교차검증 - K-Fold와 Stratified K-Fold의 이해 (0) | 2022.09.29 |