1. 목표 및 중요성


따릉이는 서울시의 친환경사업과 함께 시민들에게 이동수단을 제공하기 위해 2015년부터 현재까지 계속 이루어지고 있는 사업이다. 실제로 시민들은 가까운 거리를 가거나 출퇴근, 산책, 운동을 하는 등 여러 방면에서 따릉이를 이용하고 있다.
서울시 공공자전거 따릉이의 회원 수는 350만명을 넘어섰다. 일 평균 이용 건수는 약 9만건에 다다랐다. 따릉이를 효율적으로 운영하기 위해서 직원들이 대여소의 실시간 거치율을 확인하고, 70%의 거치율을 유지하고자 노력한다. 하지만 무조건 거치율을 유지하는 것 보다는 따릉이 재분배 문제는 단순 거치율의 문제가 아닌 장소별, 시간대별 수요예측이 중요하다. 왜냐하면 출근시간이나 퇴근시간과 같은 여러가지 경우의 수가 고려되어야 하기 때문이다.
그리고 회수율 = (반납건수 -대여건수) / 100 로 계산하여, 각 대여소별로 원 크기로 나타내었다. 즉, 원이 클수록 대여보다 반납건수가 많아 잉여 자전거가 존재하며, 원이 작을수록(특히 -값인 것) 자전거가 부족한 대여소이다. 이것을 통해 각 대여소마다 회수율의 차이가 크게 나타나므로 수요 예측을 통한 분배 문제를 해결하는 것이 중요하다고 볼 수 있다.
2. 데이터셋 설명








서울 열린데이터 광장(https://data.seoul.go.kr/dataList/OA-14994/F/1/datasetView.do)에서 서울 특별시 공공자전거 시간대별 대여건수 데이터와 서울특별시 공공자전거 대여이력정보 데이터를 사용하였다. 단, 기간은 2022년 1월~12월로 제한하였다. 외부데이터를 함께 사용하기 위해 날씨 사이트에서 정보를 크롤링하여 데이터로 사용하였다. 또한 공공데이터 포털에서 서울특별시 각 시간별 평균 미세먼지를 사용하였다. (https://freemeteo.co.uk/weather/seoul/history/daily-history/?gid=1835848&station=10565&date=2022-01-01&language=english&country=south-korea)(https://www.data.go.kr/data/15089266/fileData.do )( https://www.data.go.kr/data/15089266/fileData.do )
3. EDA


[자전거 대여량 EDA]
-성별과 이용 타입의 연관성 분석
모든 사용 타입에서 남성이 더 많이 이용한다는 사실을 알 수 있다.
-나이와 이용권 타입의 연관성 분석
이것을 통해서 단체권은 40대가 많이 사용하며, 일일권과 정기권은 20대에서 유독 많이 사용되는 것을 볼 수 있다. 그리고 전체적으로 20대 사용자가 가장 많으며, 나이가 많을수록 사용자가 적어지는 경향이 보인다. 단체권은 학교나 회사에서 제공하여 10~40대까지 여러 연령층에서 사용자가 나오는 것으로 추측할 수 있다.



-계절과 이용권 타입 분석
모든 이용권 타입에서 여름과 겨울에 이용량이 적다는 사실을 알 수 있다. 그리고 여름보다는 겨울에 특히 이용량이 적어지는 것을 확인하였다.
-시간과 이용권 타입 분석
정기권은 출근과 퇴근시간에 이용량이 급격히 증가하는 것을 확인할 수 있고, 일일권도 또한 퇴근시간에 사용량이 늘어남을 알 수 있다. 단체권은 조금 다른 양상이 보이는데 15~16시에 사용량이 많은 것을 확인할 수 있다. 10대가 가장 많이 사용하는 것이 단체권이라 10대의 하교시간이 영향을 미친 것으로 보인다.
-요일과 이용권 타입 분석
0~6까지 ‘월화수목금토일’ 순이다. 일일권과 단체권에서 주말과 휴일에 사용량이 급증하는 것을 확인할 수 있고 정기권은 평일에 이용량이 많고 주말과 휴일에는 이용량이 적어지는 것을 확인할 수 있다.

-바람세기, 불쾌지수와 이용권 타입 분석
5계급 정도가 바람이 사람의 행동에 영향을 주는 기준으로 판단했다. 만약 갖고 있는 데이터의 바람세기가 5계급 미만이면 바람이 사람의 행동에 제약을 준다고 말하기 힘들것이다. 5 계급이 바람의 세기 29부터이므로 바람의 세기가 사람에 영향을 주는 지점(29 이상) 이상일 때, 바람에게 영향을 받았다고 가정하였다.
바람세기에서는 정기권, 일일권, 단체권 모두에서 이용량에 영향을 줄만한 강한 바람의 세기일 때, 이용량이 더 높았다.
또한 불쾌지수가 높을수록 모든 이용권 타입에서 이용량이 증가하는 추세를 보인다.


-미세먼지와 이용권 타입 분석
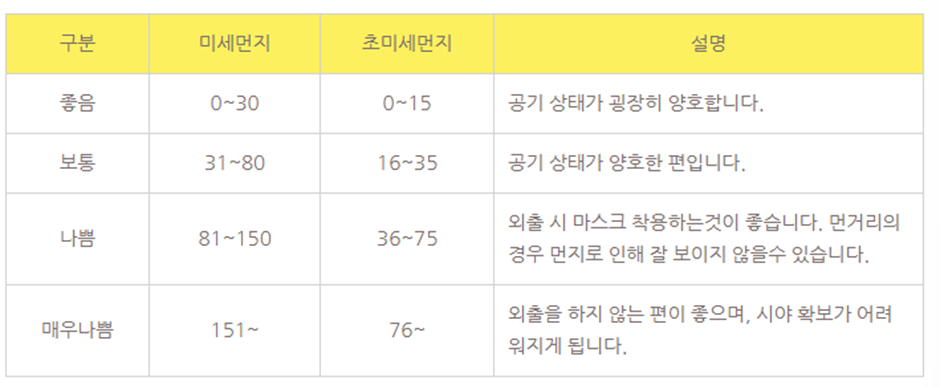
기준에 따라 좋음, 보통, 나쁨, 매우나쁨으로 구분해서 새로운 칼럼을 제작하여 추세를 확인하였다.
정기권을 제외한 일일권, 단체권에서는 미세먼지가 많은 날에는 이용량이 줄어드는 것을 확인할 수 있다. 정기권의 경우에서 미세먼지가 매우 나쁜 경우에는 이용량이 줄어들지 않았다고 나왔지만 신뢰구간을 통해 보았을 때, 불확실성이 높으므로 이용량이 무조건 많다고 단정할 수 없다.
-초미세먼지와 이용권 타입 분석
초미세먼지의 경우에서는 모든 이용권 타입에서 미세먼지가 심할수록 사용량이 적어지는 것을 확인할 수 있다.
4. 모델 적합

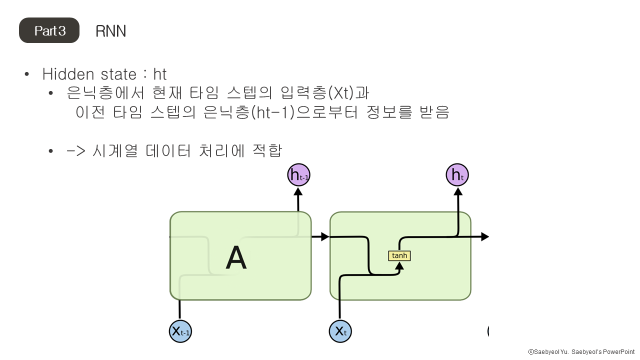



1) Recurrent Neural Networks (RNN)
RNN은 hidden layer가 순환하는 구조를 가진 neural network다. 특정 시점에서 layer의 input으로 이전 시점의 hidden state와 현재 시점의 데이터를 받아 처리하고 다음 layer에 hidden state를 넘겨주며 순차적으로 forward pass가 이루어진다. 현재 시점의 데이터를 처리할 때 이전 시점의 상태를 고려한다는 것은 현재 시점의 정보가 이전 시점에 영향을 받는다는 것을 가정하고 있으므로 RNN은 시계열 데이터 처리에 적합하다. 시계열 예측이 목적인 본 프로젝트에서는 RNN 계열의 모델을 사용하기로 결정했다.

2) Long short-term memory (LSTM)
RNN은 처리하는 시계열 데이터의 길이가 커질수록 역전파 시에 gradient의 크기가 매우 줄어 학습이 일어나지 않는 문제가 생긴다. 이런 gradient vanishing을 해결하기 위해 LSTM은 RNN에 hidden state와 더불어 cell state를 추가하였다.
Cell state는 forget gate와 input gate의 연산으로 결정된다. Forget gate는 이전 시점의 hidden state와 현 시점의 input이 sigmoid를 통과하여 이전 시점의 cell state와 곱해지는 과정이다. 즉 이전 시점의 state를 얼마큼 반영할 것인지 결정한다. Input gate 또한 이전 시점의 hidden state와 현 시점의 input이 sigmoid와 tanh를 각각 통과하여 Hadamard product(element-wise product)을 하여 cell state에 더해주는 과정이다. 따라서 현 시점의 state를 얼마큼 반영할 것인지 결정하는 역할을 한다. 마지막으로 output gate는 forget gate와 input gate로 결정된 cell state를 통해 hidden state를 결정하는 연산이다.

LSTM은 RNN에 비해 장기의존성이 있는 시계열 데이터를 잘 모델링하고 기울기 소실을 완화할 수 있으며 더 복잡한 데이터를 다룰 수 있다. 따라서 본 프로젝트에서는 시계열 데이터를 학습하기 위해 LSTM을 사용했다. 그러나 RNN과 LSTM은 하나의 크기가 고정된 벡터에 state를 표현하기 때문에 정보의 손실이 발생할 수 있다는 한계점이 존재한다.
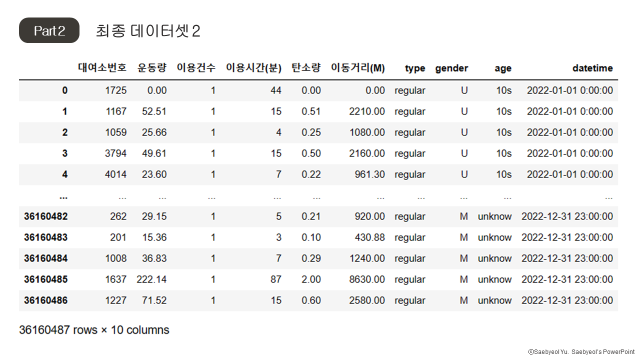
-학습을 위한 데이터 프레임 가공
서울시 공유 자전거 데이터셋의 형태는 이용자 한 명의 단일 이용 기록 단위로 구성되어 있다.
먼저 기존의 데이터를 대여소별로 나눈 뒤 한시간 단위로 이용기록을 모아 시간 당 여러 이용량의 형태로 변환하였다. 또한 날씨(기온, 습도), 대기(미세먼지, 초미세먼지) 데이터를 추가하여 학습 데이터를 구성하였다.
학습에 사용한 feature는 다음과 같다.
- 대여: 한시간 동안의 대여 수
- 대여_이용거리: 한시간 동안의 대여 후 이동거리 합
- 대여_이용시간: 한시간 동안의 대여 후 이용시간 합
- 반납: 한시간 동안의 반납 수
- 반납_이용거리: 한시간 동안의 반납 전 이동거리 합
- 반납_이용시간: 한시간 동안의 반납 전 이용시간 합
- 반납-대여: 반납과 대여의 차
- Temperature: 특정 시간의 섭씨 온도
- Rel. humidity: 특정 시간의 습도
- 미세먼지(PM10): 특정 시간의 미세먼지 농도
- 초미세먼지(PM2.5): 특정 시간의 초미세먼지 농도
-결측치 처리
서울특별시 공공자전거 대여이력 정보 데이터는 결측치가 많지않아 결측치를 삭제하였고, 날씨와 미세먼지 데이터는 전후 평균으로 결측치를 채워주었다.
-데이터 표준화
학습시에는 이용량이 가장 많은 강서구의 187개 대여소 데이터를 하나로 concat하여 이용하였다. 학습 전에는 데이터를 정규화(-1~1) 시켜줬는데 데이터의 대부분의 피처가 정규분포를 따르지 않았기 때문에 표준화 대신 Minmax scale을 적용하였다.
5. 모델 평가 및 결과 분석

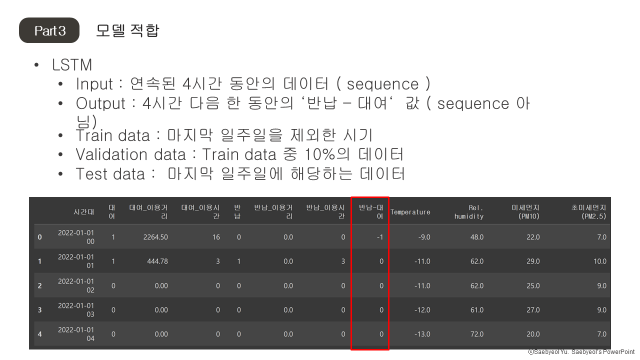
연속된 네 시간 동안의 데이터를 input으로 다음 한 시간 동안의 ‘반납-대여’ 값을 예측하도록 학습하였다. 따라서 LSTM의 한 셀에서 input의 크기는 모든 피처의 개수(11개)이고, 모델 output의 크기는 1이다. Hidden layer의 size는 36으로 설정하였고 LSTM의 층은 두개로 쌓았다. 또한 overfitting을 방지하고자 dropout을 0.2로 주었다. Loss는 MSE를 사용했으며 학습도중에 validation loss가 10번 연속으로 감소하지 않으면 학습을 멈췄다. 학습 데이터셋의 크기가 충분히 크다고 판단되고 약 한시간의 긴 학습 시간이 소요되기 때문에 Cross Validation은 사용하지 않았다. Test data를 얻기 위해 마지막 일주일의 데이터를 학습 전에 뺐으며, 학습 시에는 train data의 10%를 validation data로 사용하였다.
테스트 데이터를 이용하여 특정 대여소의 일주일 동안의 수급의 차를 예측한 값과 참값이다. 수급의 차(반납-대여)가 양수면 대여소에 자전거가 공급되고 음수면 빠져나간다는 뜻이다. 절댓값이 커질수록 과다공급, 과다수요가 발생하기 때문에 적절한 분배가 필요하다.
6. 결론


대여소의 자전거 수급의 차이를 예측하는 모델은 출퇴근 시간과 같이 이용량이 급증하는 시간대에 각 대여소별 수급을 미리 예측하고 대응할 수 있다. 예를 들어 다음 그래프는 두 대여소에 대한 일주일 동안의 예측 값이다. 그래프를 보면 특정 시간대에 3754번 대여소는 예측 값이 음수, 1178번 대여소는 양수인 경우가 있다. 이때 대여소 직원들은 3754번 대여소에서 1178번 대여소로 자전거를 배치하는 루트를 미리 계획하고 효율적으로 움직일 수 있다.
5. Code
작업마다 새로 ipynb 파일을 생성해서 작업하여 파일 수가 많지만, 참고차 깃허브 링크를 겁니다. 참고 부탁드립니다.
'데이터사이언스 > 프로젝트' 카테고리의 다른 글
| [프로젝트] 당뇨병 환자 식단 최적화 (1) | 2024.01.03 |
|---|---|
| [프로젝트] 보험 사기 예측 모델 (3) | 2023.12.27 |
| [프로젝트] 여러가지 변수에 따른 개인 별 의료비 예측 (0) | 2023.02.02 |
| [프로젝트] 음식 선호도에 기반한 당뇨병 환자의 식단 제공 프로그램 part. 2 (0) | 2022.12.19 |
| [프로젝트] 음식 선호도에 기반한 당뇨병 환자의 식단 제공 프로그램 part. 1 (0) | 2022.06.27 |